
DreamVoice: Text-guided Voice Conversion
Jiarui Hai1*, Karan Thakkar1*, Helin Wang1, Zengyi Qin2,3, Mounya Elhilali1
1Johns Hopkins University, Baltimore, MD, USA
2Massachusetts Institute of Technology, Cambridge, MA, USA
3MyShell.ai, USA
*equal contribution
Introduction
DreamVoice is an innovative approach to voice conversion (VC) that leverages text-guided generation to create personalized and versatile voice experiences. Unlike traditional VC methods, which require a target recording during inference, DreamVoice introduces a more intuitive solution by allowing users to specify desired voice timbres through text prompts.
Demo
| Source | Prompt | DreamVC | DreamVG+ReDiffVC | DreamVG+FreeVC |
|---|---|---|---|---|
| A smooth young voice with a gender-neutral tone, that sounds cute. | ||||
| Authoritative sounding person, who is gender-ambiguous and adult. | ||||
| Senior's voice who can sound like a male or female with a smooth voice, perfect for storytelling. | ||||
| A female adult voice with a warm and bright voice, perfect for client and public interaction. | ||||
| A dark, smooth, and authoritative adult female voice, who sounds attractive and ideal for storytelling. | ||||
| A teenage girl's voice, characterized by brightness, smoothness, and nasal quality. | ||||
| Rough sounding attractive teenage girl with a voice suited for client and public interaction. | ||||
| A teenage girl's voice that is smooth, warm, and attractive, perfect for captivating storytelling. | ||||
| A senior female voice, dark, authoritative, and strong, ideal for diplomacy and judiciary roles. | ||||
| A senior woman's voice carries with warmth, depth, and an authoritative tone. | ||||
| Adult male voice, dark and smooth, authoritative and attractive. | ||||
| A mature male voice, bright and engaging, good for client and public interaction. | ||||
| Young boy with a bright, weak, and nasal voice. | ||||
| Teenager's voice that is rough and weak. | ||||
| A senior male voice, with a rough texture. |
Method
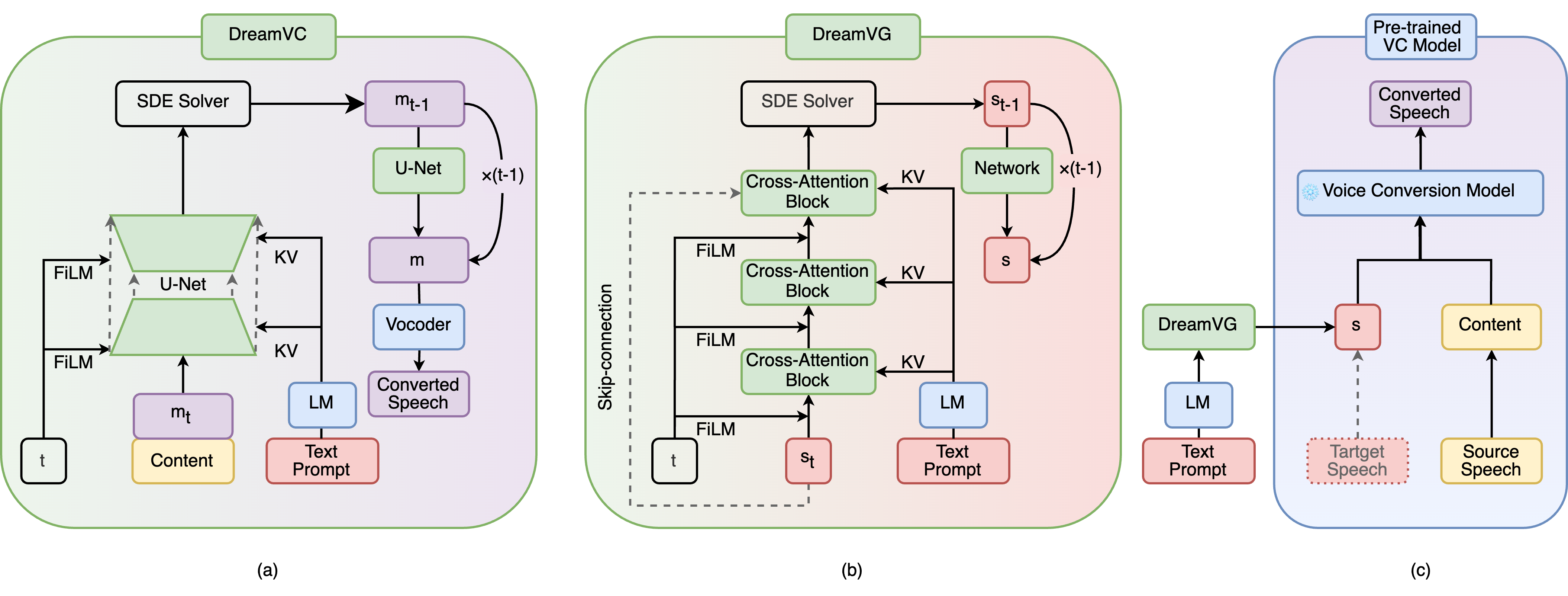
Overview of the (a) DreamVC, (b) DreamVG, and (c) Plugin Strategy.
-
-
-
- Dashed lines represent skip connections.
-
-
-
-
-
-
-
-
-
Modules in Blue are pre-trained models and remain Frozen during training, while Modules in Green are Trainable.-
Yellow Blocks represent the source speaker's Content Information while Red Blocks represent the target speaker's Timbre Information.-
Purple blocks correspond to the Converted Speech.- Dashed lines represent skip connections.
-
LM represents the Language Model.-
KV represents Cross-Attention (Vaswani et al., 2017) and FiLM represents Feature-wise Linear Modulation layers (Perez et al., 2018) used for fusing Text Prompt and diffusion step t respectively.-
SDE solver is the stochastic differential equations for the diffusion sampling.-
Prompt is the text description about the desired target voice.-
t is the diffusion step.-
Content is the content embedding of the source speaker.-
s is the speaker embedding of the target voice.-
m is the mel-spectrogram.-
m_t and s_t represent the noisy versions of the mel-spectrogram and the speaker embedding at the diffusion step t.