Education


Experience




About Me
I am a fourth-year PhD student at Johns Hopkins University, where my research focuses on audio and speech signal processing, with an emphasis on diffusion-based generative models and multimodal audio–language understanding.
I am also an active music producer and am always exploring research projects that unlocks new possibilities in audio and music production.
Introducing OpenSound
News
† Research mentorship
Research Highlights

CapSpeech: Enabling Downstream Applications in Style-Captioned Text-to-Speech
A style-captioned TTS dataset and framework enabling controllable, style-aware text-to-speech for downstream applications.
Dataset IEEE Transactions on Audio, Speech and Language Processing (TASLP) | 2026
CapSpeech: Enabling Downstream Applications in Style-Captioned Text-to-Speech
A style-captioned TTS dataset and framework enabling controllable, style-aware text-to-speech for downstream applications.
Dataset IEEE Transactions on Audio, Speech and Language Processing (TASLP) | 2026

FlexSED: Towards Open-Vocabulary Sound Event Detection
An open-vocabulary sound event detection approach that generalizes to unseen classes via flexible text-conditioned modeling.
Spotlight IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) | 2025
FlexSED: Towards Open-Vocabulary Sound Event Detection
An open-vocabulary sound event detection approach that generalizes to unseen classes via flexible text-conditioned modeling.
Spotlight IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) | 2025
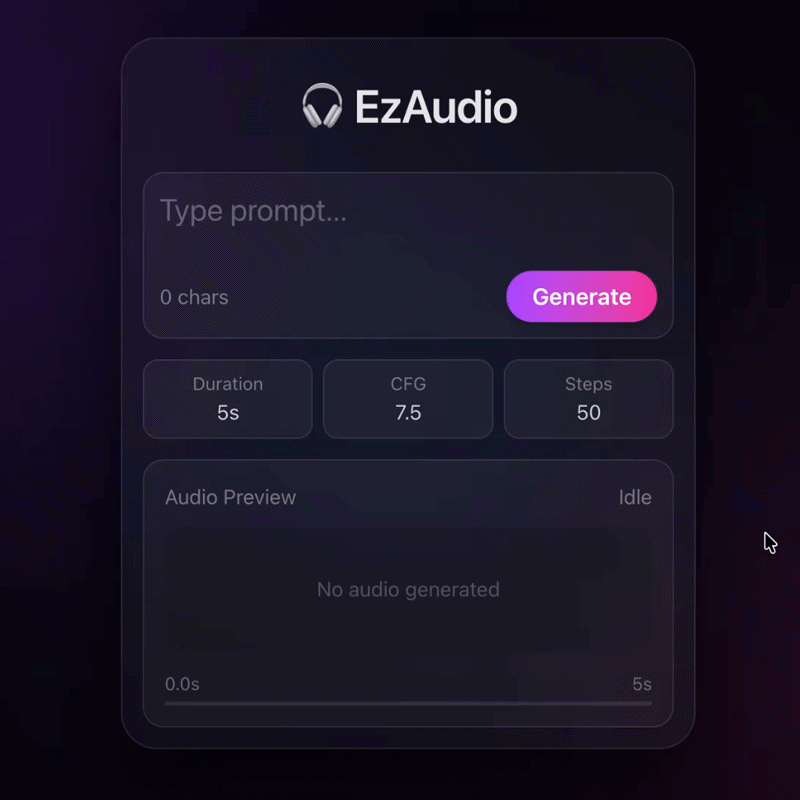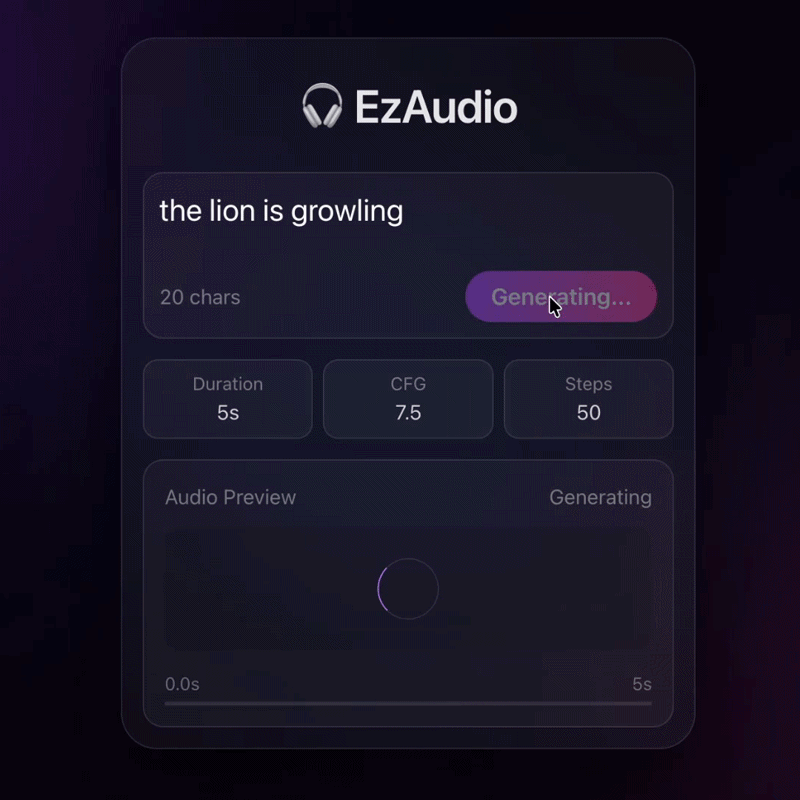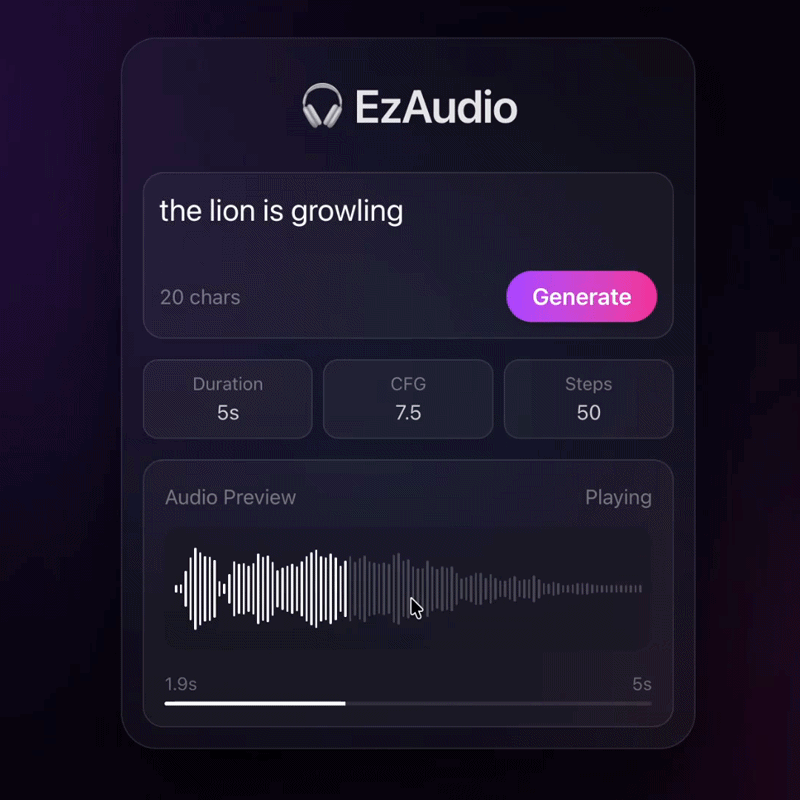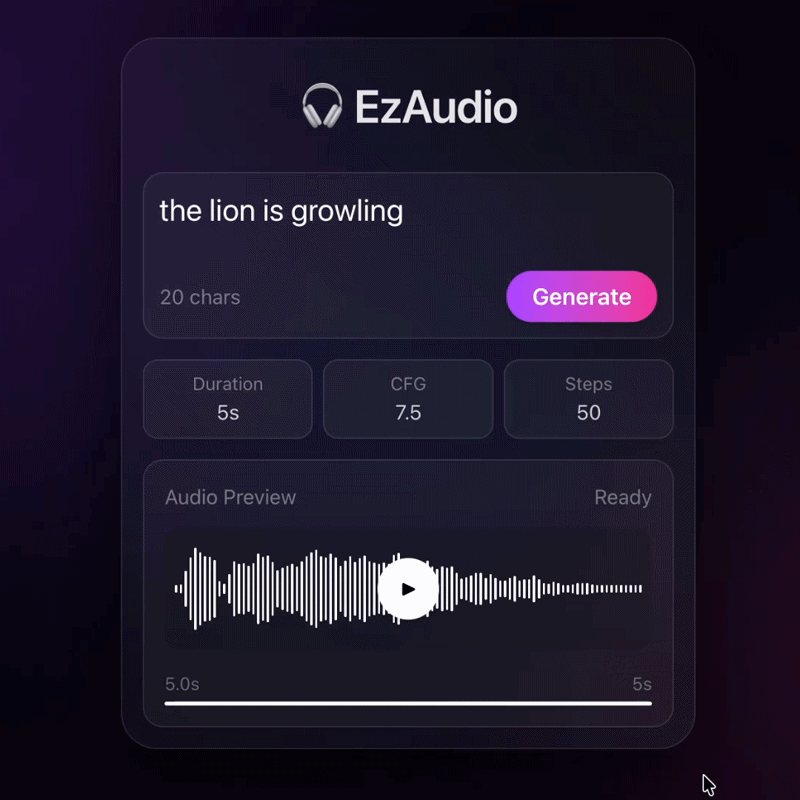
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
An efficient diffusion transformer that improves text-to-audio generation quality while reducing compute.
Oral Interspeech | 2025
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
An efficient diffusion transformer that improves text-to-audio generation quality while reducing compute.
Oral Interspeech | 2025
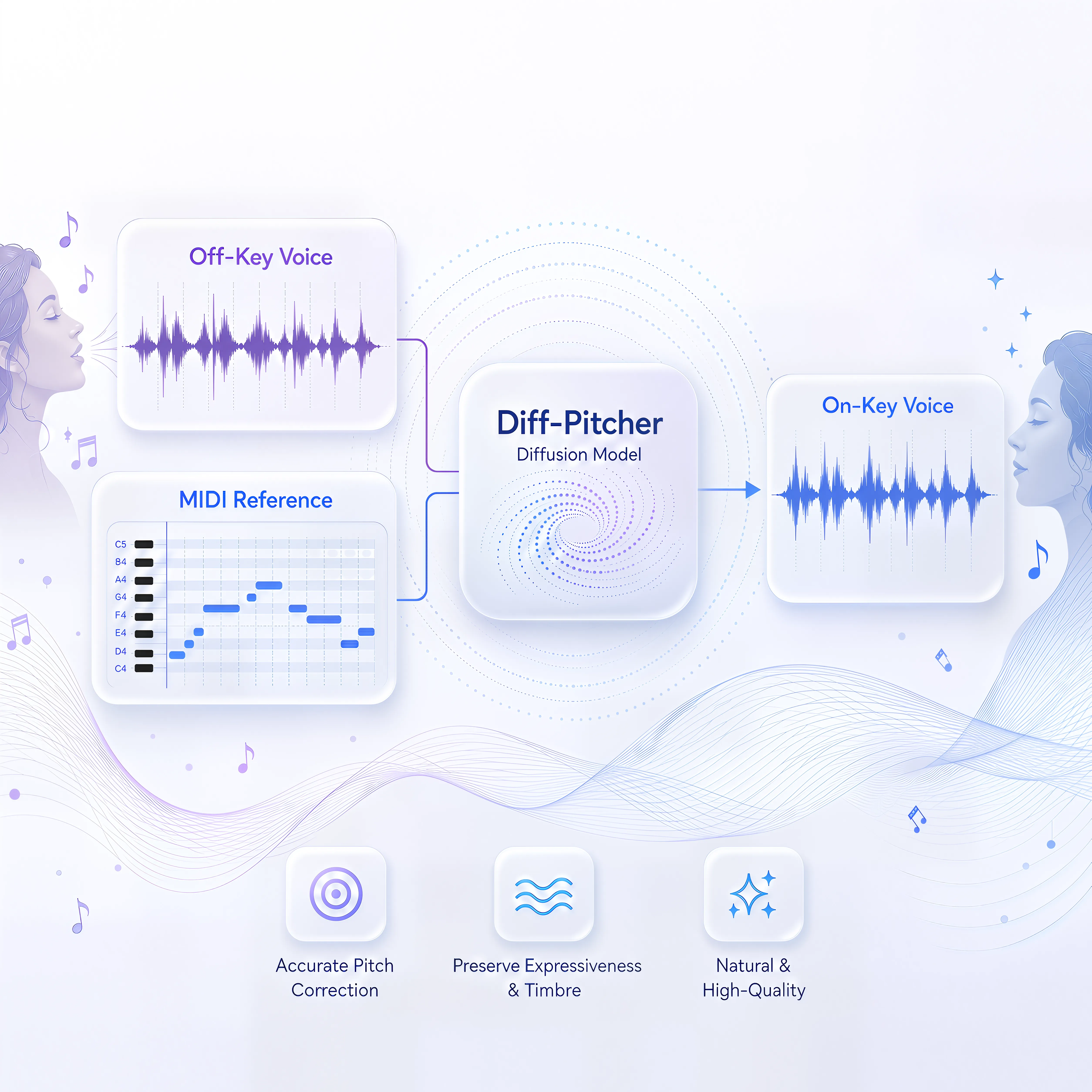
Diff-Pitcher: Diffusion-based Singing Voice Pitch Correction
A diffusion-based method for singing voice pitch correction that adjusts pitch while preserving timbre and expression.
Oral IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) | 2023
Diff-Pitcher: Diffusion-based Singing Voice Pitch Correction
A diffusion-based method for singing voice pitch correction that adjusts pitch while preserving timbre and expression.
Oral IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) | 2023
More Projects
Education
Experience