2026

CapSpeech: Enabling Downstream Applications in Style-Captioned Text-to-Speech
A style-captioned TTS dataset and framework enabling controllable, style-aware text-to-speech for downstream applications.
Dataset IEEE Transactions on Audio, Speech and Language Processing (TASLP)
CapSpeech: Enabling Downstream Applications in Style-Captioned Text-to-Speech
A style-captioned TTS dataset and framework enabling controllable, style-aware text-to-speech for downstream applications.
Dataset IEEE Transactions on Audio, Speech and Language Processing (TASLP)

Summary of The Inaugural Music Source Restoration Challenge
A summary of the inaugural Music Source Restoration Challenge, covering tasks, data, baselines, and key findings.
Challenge IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Summary of The Inaugural Music Source Restoration Challenge
A summary of the inaugural Music Source Restoration Challenge, covering tasks, data, baselines, and key findings.
Challenge IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
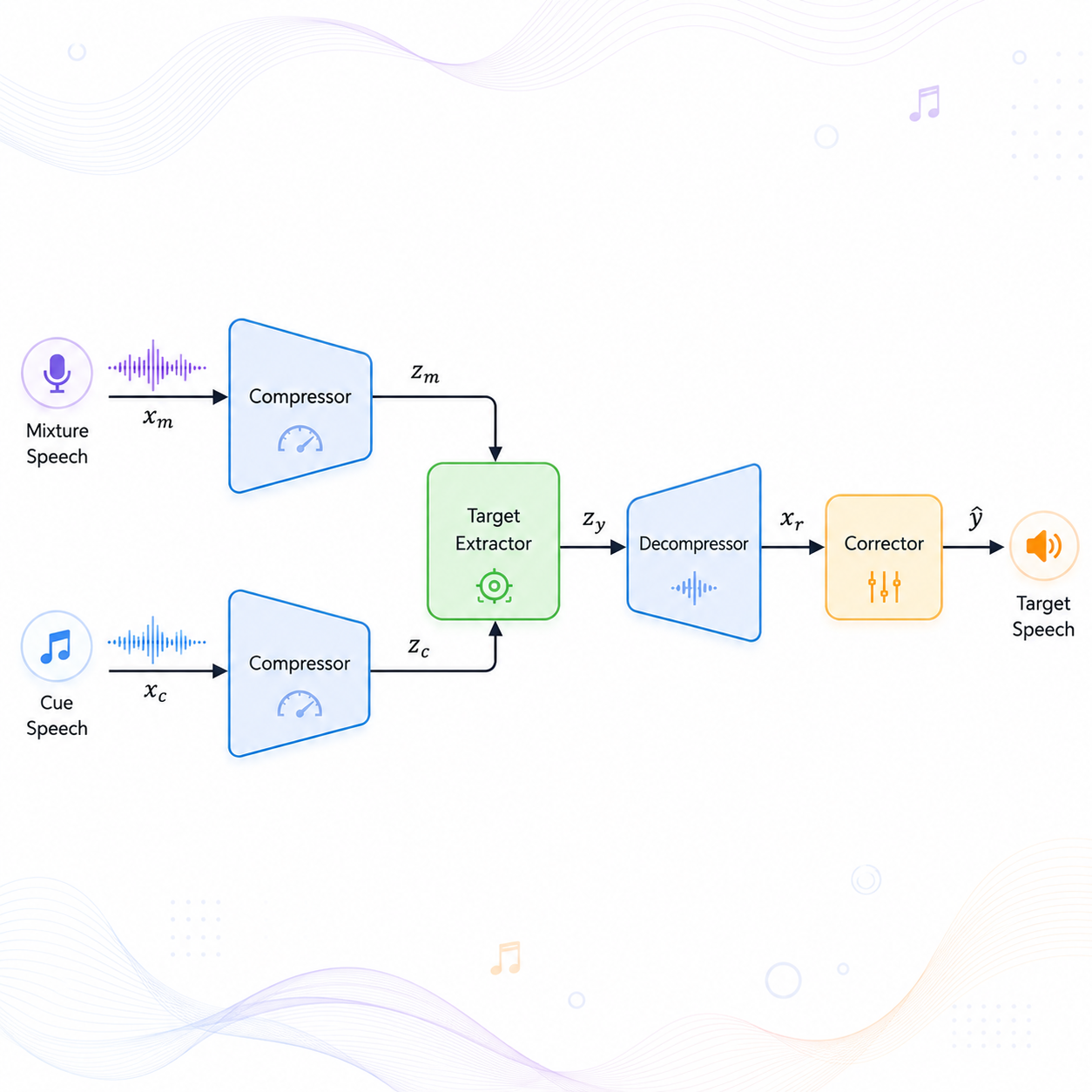
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction Through a Cascaded Generative Pipeline
A cascaded generative pipeline for target speech extraction that improves intelligibility and perceptual quality.
IEEE Transactions on Audio, Speech and Language Processing (TASLP)
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction Through a Cascaded Generative Pipeline
A cascaded generative pipeline for target speech extraction that improves intelligibility and perceptual quality.
IEEE Transactions on Audio, Speech and Language Processing (TASLP)
2025

FlexSED: Towards Open-Vocabulary Sound Event Detection
An open-vocabulary sound event detection approach that generalizes to unseen classes via flexible text-conditioned modeling.
Spotlight IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)
FlexSED: Towards Open-Vocabulary Sound Event Detection
An open-vocabulary sound event detection approach that generalizes to unseen classes via flexible text-conditioned modeling.
Spotlight IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
An efficient diffusion transformer that improves text-to-audio generation quality while reducing compute.
Oral Interspeech
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
An efficient diffusion transformer that improves text-to-audio generation quality while reducing compute.
Oral Interspeech
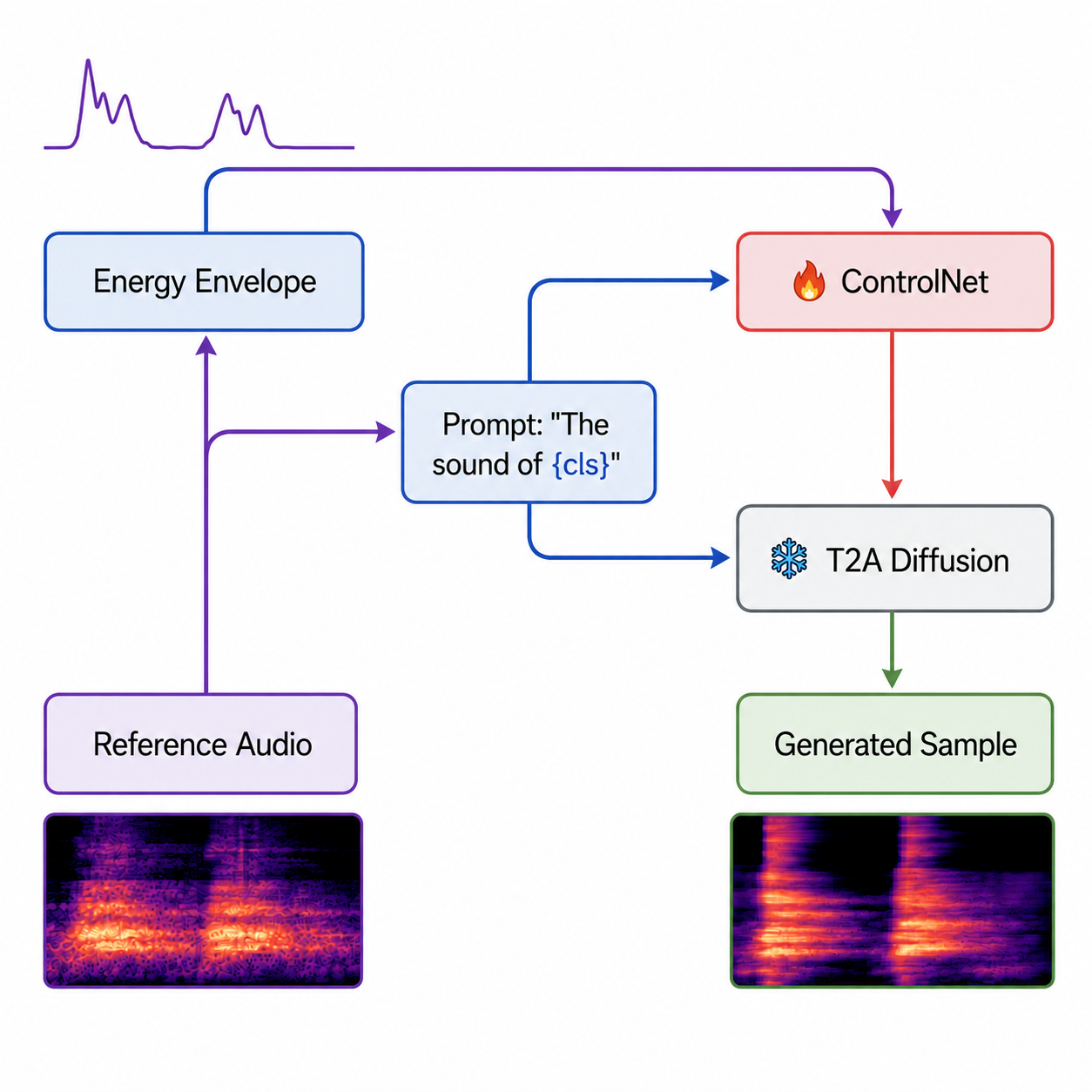
SynSonic: Augmenting Sound Event Detection through Text-to-Audio Diffusion ControlNet and Effective Sample Filtering
A text-to-audio diffusion ControlNet augmentation pipeline with sample filtering to improve sound event detection.
IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)
SynSonic: Augmenting Sound Event Detection through Text-to-Audio Diffusion ControlNet and Effective Sample Filtering
A text-to-audio diffusion ControlNet augmentation pipeline with sample filtering to improve sound event detection.
IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)
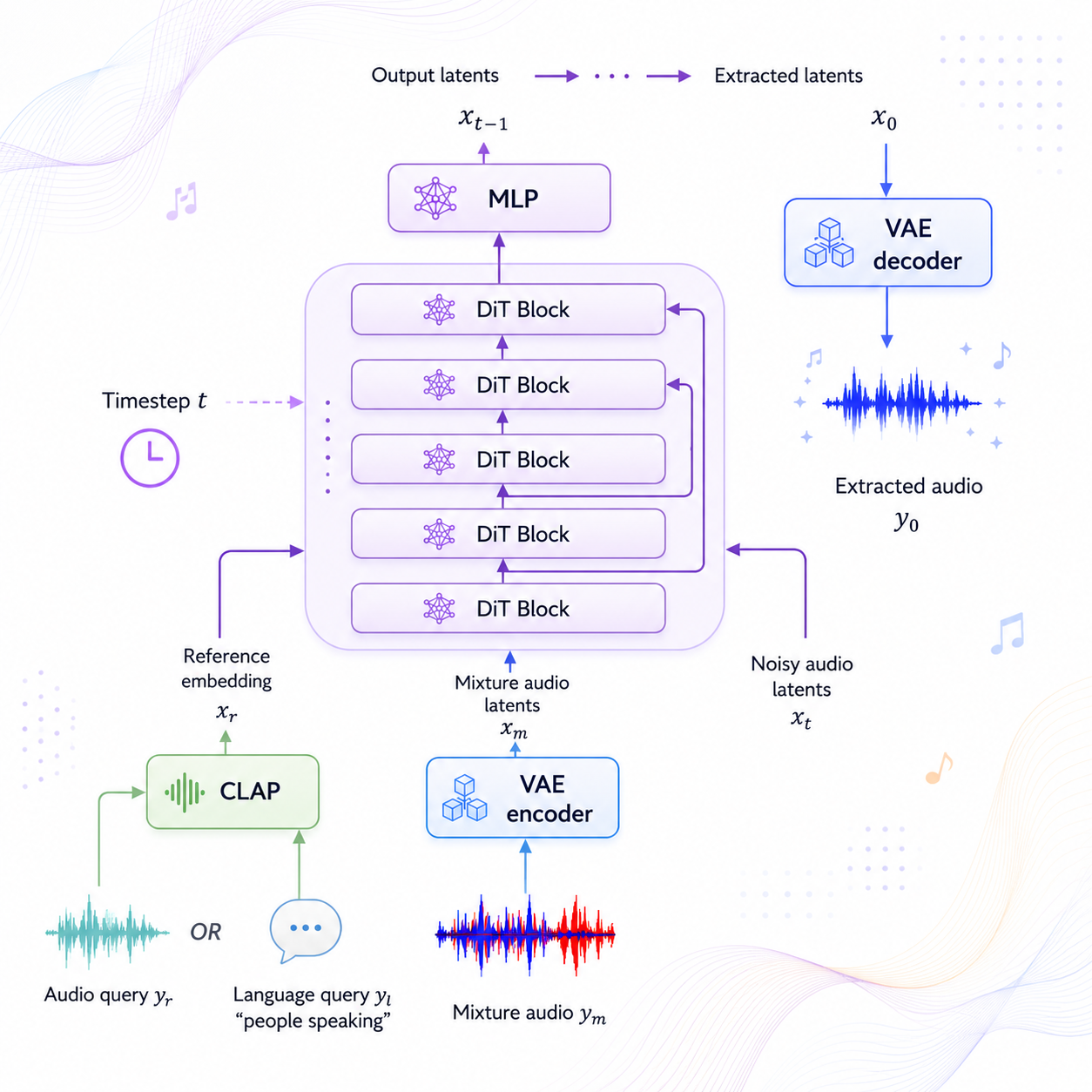
SoloAudio: Target Sound Extraction with Language-Oriented Audio Diffusion Transformer
A language-conditioned audio diffusion transformer for target sound extraction from mixtures.
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
SoloAudio: Target Sound Extraction with Language-Oriented Audio Diffusion Transformer
A language-conditioned audio diffusion transformer for target sound extraction from mixtures.
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
2024
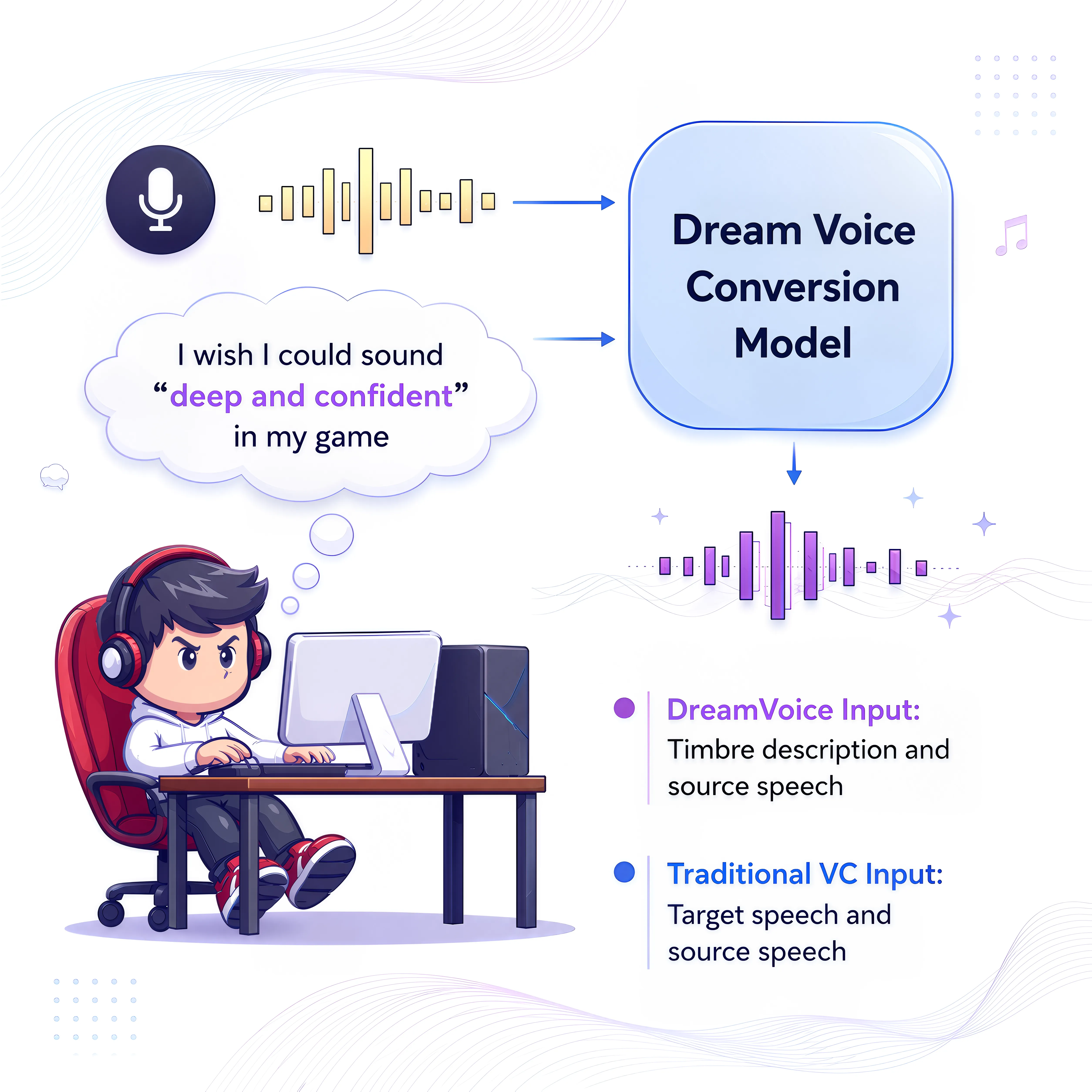
DreamVoice: Text-Guided Voice Conversion
Text-guided voice conversion that follows natural-language prompts to control voice attributes and speaking style.
Dataset Interspeech
DreamVoice: Text-Guided Voice Conversion
Text-guided voice conversion that follows natural-language prompts to control voice attributes and speaking style.
Dataset Interspeech
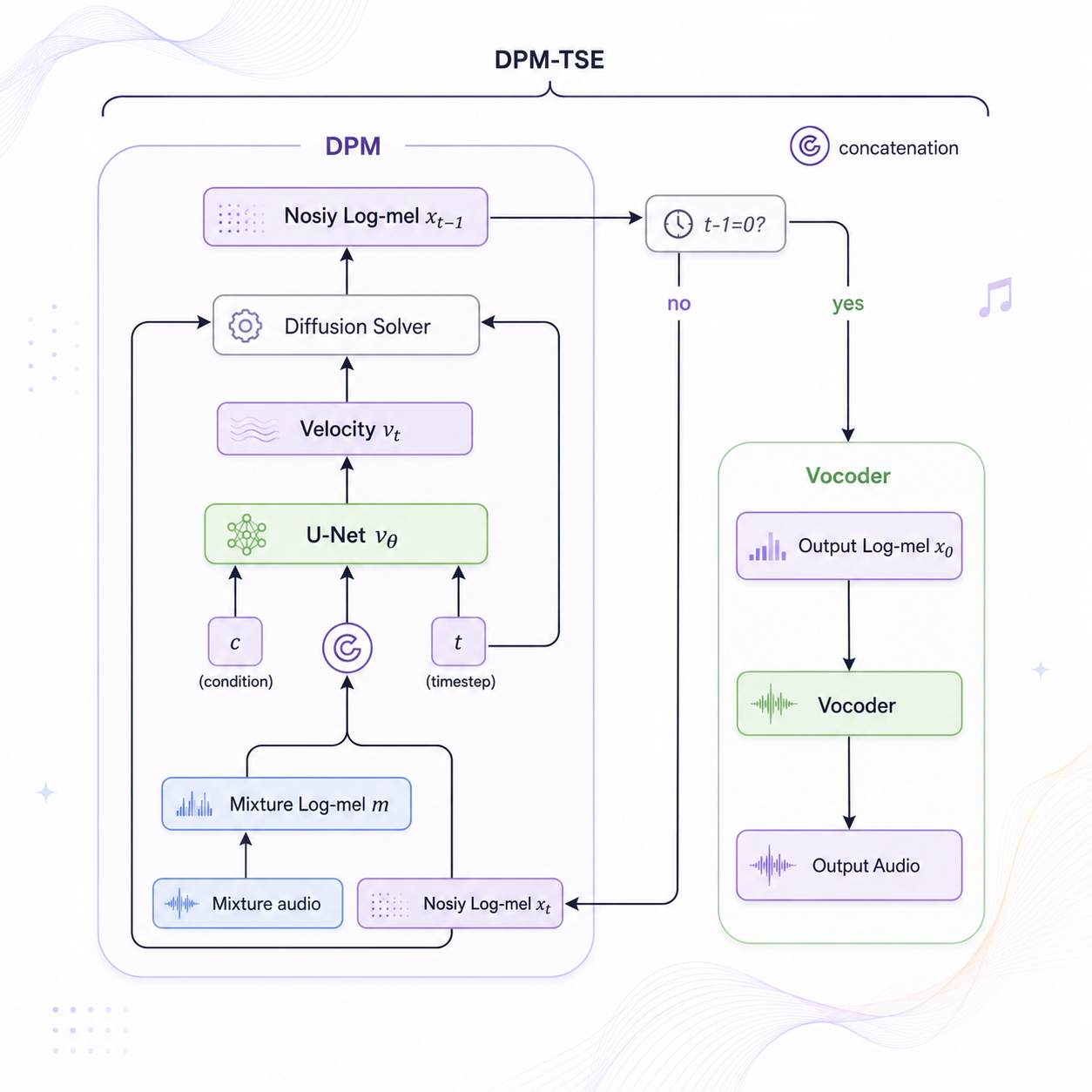
DPM-TSE: A Diffusion Probabilistic Model for Target Sound Extraction
A diffusion probabilistic model for target sound extraction that separates a desired source from audio mixtures.
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
DPM-TSE: A Diffusion Probabilistic Model for Target Sound Extraction
A diffusion probabilistic model for target sound extraction that separates a desired source from audio mixtures.
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
2023
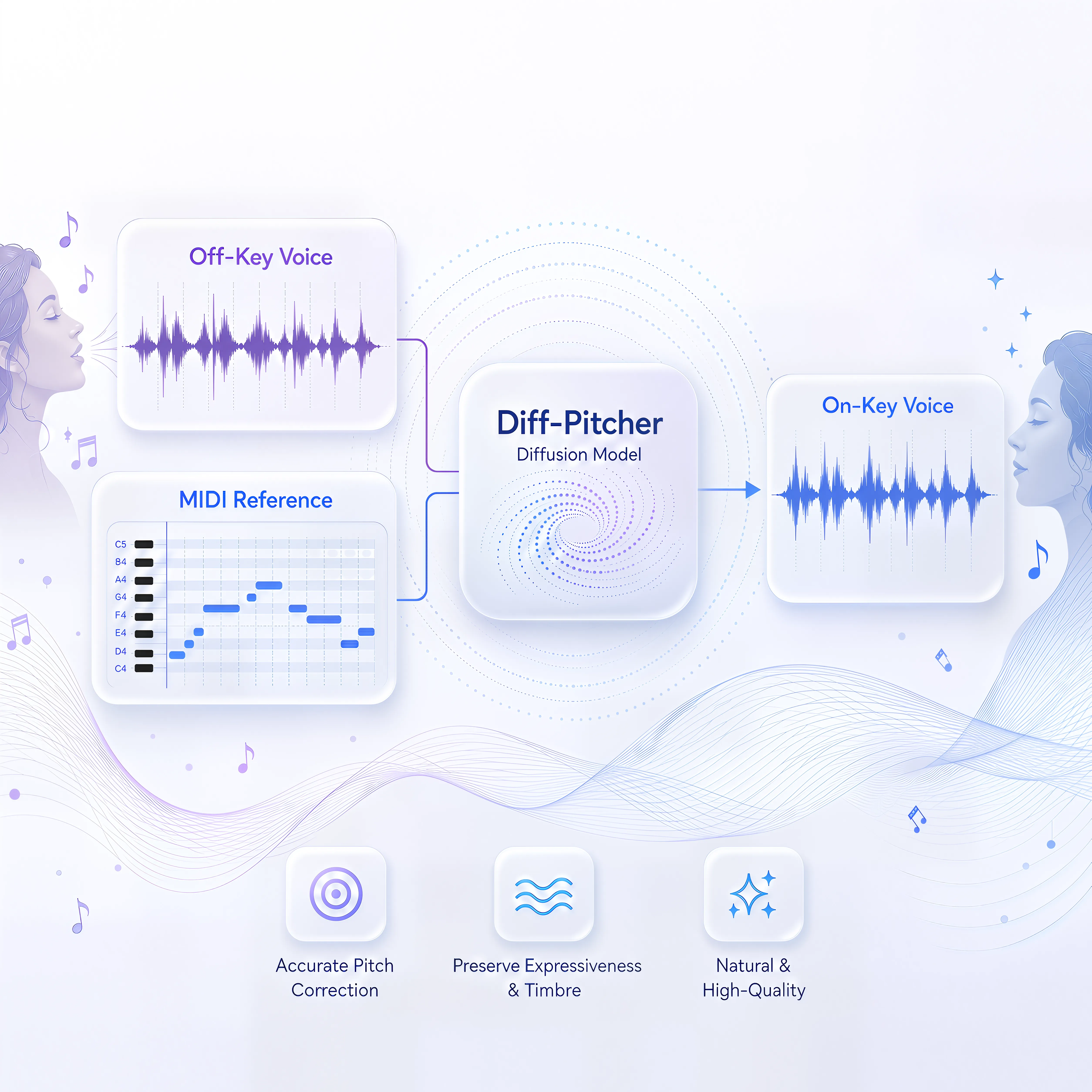
Diff-Pitcher: Diffusion-based Singing Voice Pitch Correction
A diffusion-based method for singing voice pitch correction that adjusts pitch while preserving timbre and expression.
Oral IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)
Diff-Pitcher: Diffusion-based Singing Voice Pitch Correction
A diffusion-based method for singing voice pitch correction that adjusts pitch while preserving timbre and expression.
Oral IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)
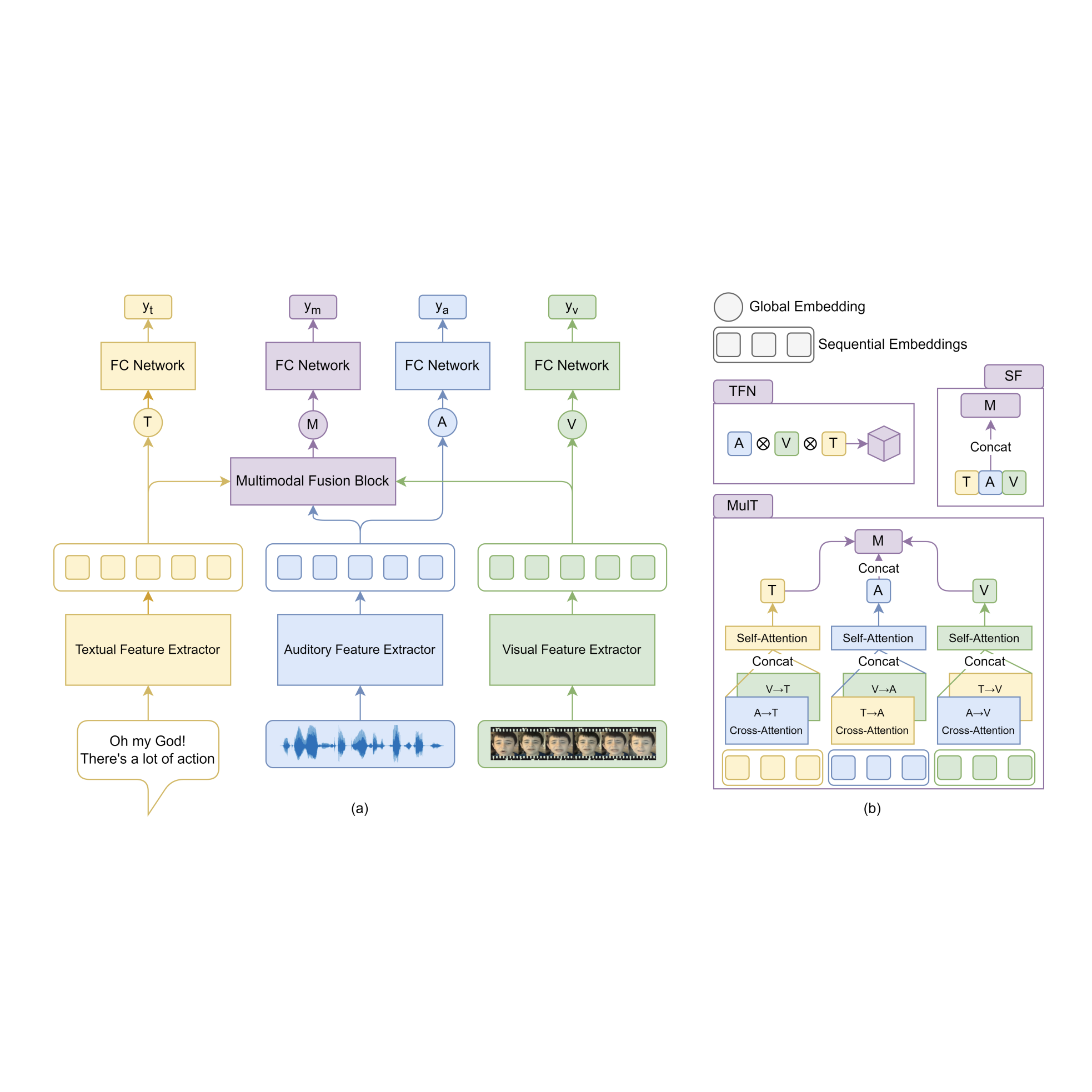
Boosting Modality Representation with Pre-trained Models and Multi-task Training for Multimodal Sentiment Analysis
Multi-task training with pre-trained modality encoders to learn stronger multimodal representations for sentiment analysis.
IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)
Boosting Modality Representation with Pre-trained Models and Multi-task Training for Multimodal Sentiment Analysis
Multi-task training with pre-trained modality encoders to learn stronger multimodal representations for sentiment analysis.
IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)